The worst data quality issues aren’t the ones that break your pipelines.
They’re the silent ones. We had one that went unnoticed for a week: a bug in an upstream application started generating duplicate order_id values. Our fct_orders table dutifully updated, our revenue numbers looked great, a little too great, in fact. It wasn’t until the finance team tried to reconcile accounts that all hell broke loose. The ensuing fire drill, the loss of trust, the manual cleanup-it was a nightmare.
After the dust settled, our mantra became “Never again.” We couldn’t rely on humans checking logs.
We needed a system that would scream at us the moment something was wrong. So we weaponized dbt test and turned it into an automated, serverless observatory.
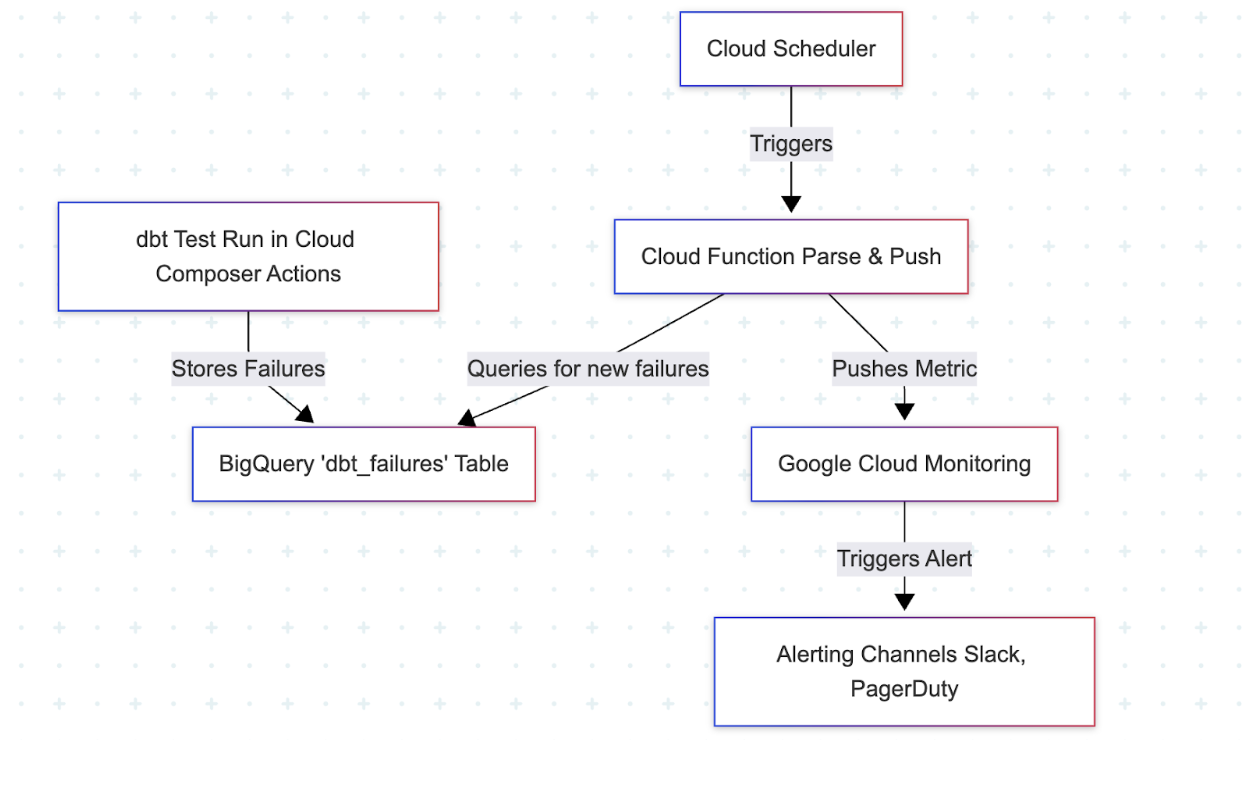
It started with being disciplined. For every critical model, like our orders table, we wrote comprehensive tests in our .yml files: unique, not_null, relationships, even custom expression tests to ensure order totals were never negative. But here’s the key: instead of just letting a dbt test failure show up as a red X in a log, we configured our CI/CD job to run with the —store-failures flag.
This command is a lifesaver; it writes the actual failing records into a table in BigQuery.
With our “data bugs” now queryable, we built an automated watchdog.
A Cloud Function, triggered by Cloud Scheduler every 15 minutes, does one simple thing: it queries that dbt_failures table. If it finds any new rows, it immediately makes an API call to Google Cloud Monitoring, pushing a custom metric called dbt_test_failure.
We enrich the metric with labels like the model name and test name. Now, our data quality isn’t buried in a log; it’s a first-class metric, just like CPU usage. We have dashboards and, most importantly, PagerDuty alerts tied to it.
If a single uniqueness test fails on the orders table, my phone buzzes before anyone in finance even has their morning coffee.
Our Data Quality Observatory:
d