I once sat in a meeting where the marketing team was presenting the results of a new campaign. The data was from the day before, pulled from our standard nightly dbt run. Midway through, a product manager pointed out that a major feature had been tweaked mid-campaign, completely changing user behavior for the last 12 hours.
Cue the silence.
That was the moment I realised our “modern” data stack, built on batch processing, wasn’t helping us. The report wasn’t just late, it was irrelevant. It was telling us what used to be true, one day later.
We had to close the loop
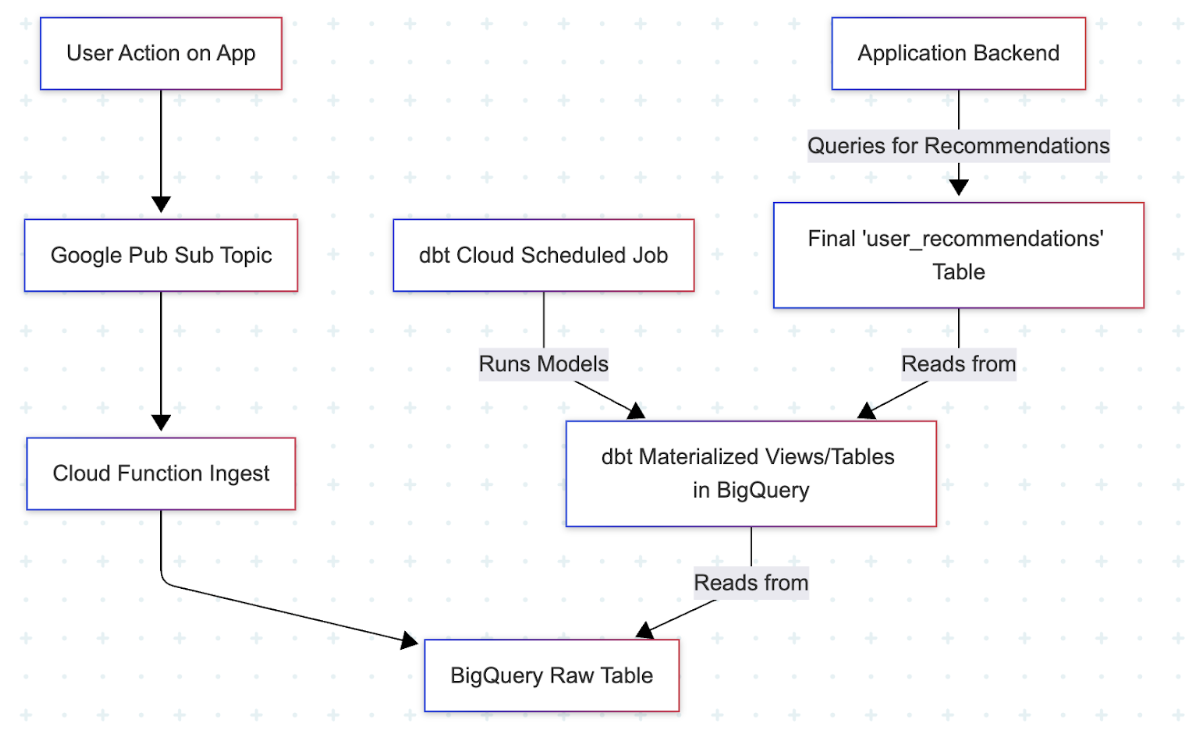
We needed to move from being data historians to being a part of the living, breathing product. Here’s how we did it. A tiny JSON event fed into a Google Pub/Sub topic. A simple, stateless Cloud Function immediately catches it and streams it into a raw table in BigQuery. The whole trip takes less than two seconds.
The real shift in mindset happened in our dbt project. We reconfigured a critical dbt Cloud job to run every ten minutes. This wasn’t a full stack refresh, but a targeted run on a few key models.
One model crunches the incoming raw events to update a user_topic_affinity score. Another joins those scores against our articles table to create a pre-calculated user_recommendations table.
So when the user returns to the homepage, the app doesn’t need to perform some complex, real time calculation.
It just runs a dead-simple
SELECT * FROM user_recommendations WHERE user_id = ?. The experience feels magically responsive to the user, but it’s powered by a robust, asynchronous pipeline we built with tools we already knew.
Our Hard-Won Architecture: